TCP服务模型

TCP提供可靠的连接,为确保这一点它提供了四种机制:
- 当收到数据后,它将发送ACK来告知发送端已经接收方已经正确收到数据。
- 利用校验和(根据报头和数据生成)来检测损坏的数据。
- 序列号检测丢失的数据。双方将标记包的序列号,如果丢失了某一段序列号,就意味着失去了相应的数据,该段数据将被重传。
- 拥塞控制,一端发送的速度远大于另一端处理的速度时,落后的一端将会告知发送端减慢发送速率直到数据被处理完毕。
TCP报文

- Sequence:指示字节流中第一个字节在TCP字节流中的位置
- Acknowledgment Sequence:指示接下来要接收的是哪个字节
- Checksum:由报头和数据计算得来
- HLEN:报头长度
- ACK:表示正在确认序列号有效
- SYN:表示正在发送同步信号
- FIN:表示连接的一个方向关闭
- PSH:告知另一端TCP层立即传送数据,而不是等待更多的数据到来
TCP连接断开

当要断开TCP连接时,A端先发送一个FIN(Finish)请求,B端确认A端没有新的数据要发送了,并停止接收新数据,B端关闭来自A to B的数据流,但是B端可能仍有数据要发送给A端,所以B端要返回ACK(Acknowledge)和要发送给A端的数据。直达B端的数据发送完了,B端会发送FIN来告知A端发送结束。A端回复ACK来确认连接结束。
UDP报文
UDP提供不可靠的连接,使用UDP协议一方面可能是因为应用程序压根不需要可靠传输,另一方面可能是应用程序有自己的纠错重传机制,所以使用UDP。

- Length:16位指定整个UDP数据报的长度(报头加上数据)
- Checksum:当使用IPv4时UDP的Checksum是可选的。如果使用它将计算报头、数据、和IP源以及协议ID
ICMP
Internet Control Message Protocol用于报告错误和诊断网络层错误。

ICMP在传输层运行,当终端主机或路由器要使用ICMP报告错误的时候,它将会把它想发送回源地址的信息放进ICMP的载荷中,并把它封装进IP数据报。
端对端原则

端对端原则指的是网络只会提供帮助。如果要求系统正常运行,则必须由应用程序来提供端对端负责,网络可以提供帮助但是不能依靠它。比如,如果要确保数据在传输中的安全,需要应用程序自身实现端到端安全性。
错误检测

Checksum是这三种检测方法中计算速度最快的,但也是正确性最低的,原因很简单加入一个bit错误的加了32而另一个bit错误的减了32那Checksum将不变,也就无法捕捉到这种错误。
CRC的计算成本相比于Checksum就高的多了,但这是值得的因为它提供了更强的正确性保证。CRC的原理是计算多项式的余数,这种计算在硬件中也很容易实现,所以CRC用在链路层。有些时候TCP/IP可以不使用Checksum,因为链路层已经使用CRC校验了。如果有一个cbit长的CRC,它可以检测任意1bit或2bit 的错误,或者长度小于cbit长的一个错误,或者任何奇数个错误。
Message authorization code把数据报和一些密文信息封装在一起。只有在获得密文以后才能拿到MAC。理论上,如果收到了一个包并且它的MAC是正确的,那就可以确定这个包没有被篡改。Message authorization code 用于Transport Layer Security,TLS,这个协议则被HTTPS使用。但MAC不保证数据的绝对正确,如果翻转1bit则有二分之一的概率得到相同的MAC,如果有16bit的CRC那可以确定是否有16bit以下的错误,但是如果有16bit的MAC则有99.998的概率检测到错误。
Checksum

Checksum的算法是,先将数据报中的Checksum字段置0,然后累加包内的每16bit字,累加过程中如果Checksum超过65535会减去65535,在遍历完整个包后翻转结果的每一个bit,作为该包的Checksum。因此将完整的数据和Checksum加起来以后应该得到0xffff。如果Checksum最后的结果为0xffff则置Checksum为0。Checksum只能确保捕捉到单个bit的错误。
CRC

CRC的做法是利用nbit的源数据提取出成cbit的错误检测数据,c要远小于n,例如,如果有1500Byte的以太帧,将产生4Byte,32bit的CRC,USB和蓝牙用的是16bit的CRC。CRC不能检测出所有的错误,如果给出两个随机的包,它们CRC相同的概率是2^-c。CRC的检测能力要远比Checksum强,它可以检测任何包里的奇数个错误,2bit错误或者任何一个长度小于cbit的错误。它不保证可以检测到其他类型的错误,但是也并不是绝对检测不到,比如一个16bit的CRC不能保证检测两个相距很远的3bit长度的错误的发生,但它有很大的概率检测到。链路层一般使用CRC它具有比较强的鲁棒性,因为链路层往往比较脆弱。
CRC算法

CRC利用多项式长除来从nbit中提取出cbit。源数据作为多项式M,包中每一个bit作为每一项的系数,如果该bit为0则该项为0如果该项为1则成为一项。例如,源数据为10011101那多项式就为x^7+x^4+x^3+x^2+1。当计算CRC时将会有多项式产生式,它由CRC算法定义。比如说,如果是USB用的CRC-16的多项式产生式就是从x^16开始一直加到1。
MAC

message authentication code的做法是传输双方共享一个密文s,这个密文是一组随机的bit。通过数据M和密文s来得到MAC c。MAC有一个特点就是如果没有s那将很难生成正确的c,也很难制造一个MAC为c的数据报。由于MAC的强加密性使得,如果仅仅是改变了M的一个bit也会得到一个完全不同的c。MAC是一种兼顾错误检测和安全性的方法,但因为要顾及安全性,使得它的错误检测性没有其他方法好。

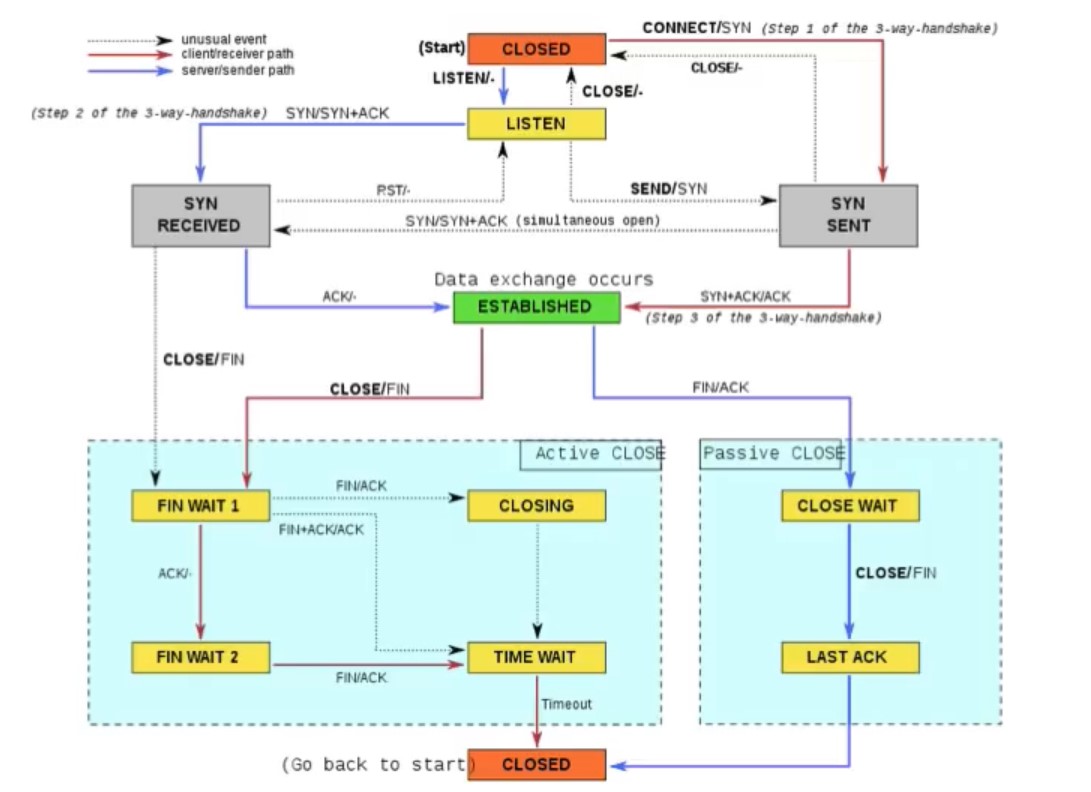
TCP状态机
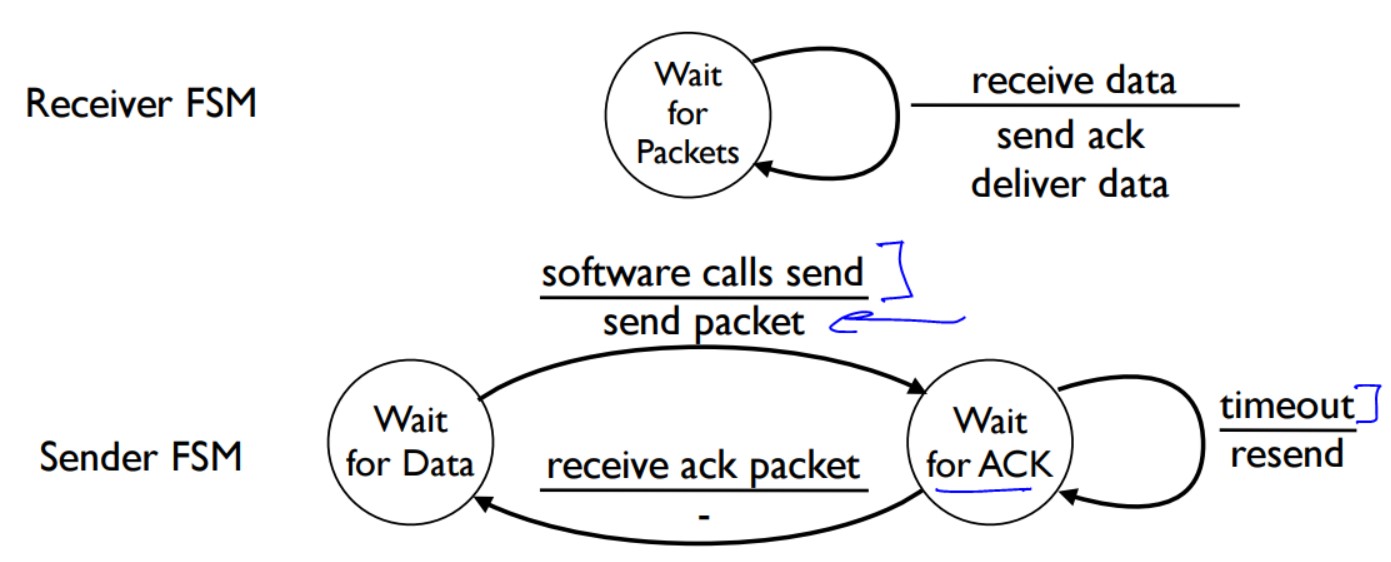
流量控制
当发送端发的包的数量大于接收端所能承受的最大容量时,流量控制就开始工作了。
流量控制最简单的工作方式就是当发送端发出一个包后它需要等待接收方发回ACK以后再继续发包,来确保自己发的包的数量没有超出接收方的接收能力,如果一直未收到接收方发回的ACK,则认为数据报丢失了,此时重发该数据报。
但是这种简单的停止-等待协议会产生问题,考虑下面这几种情况
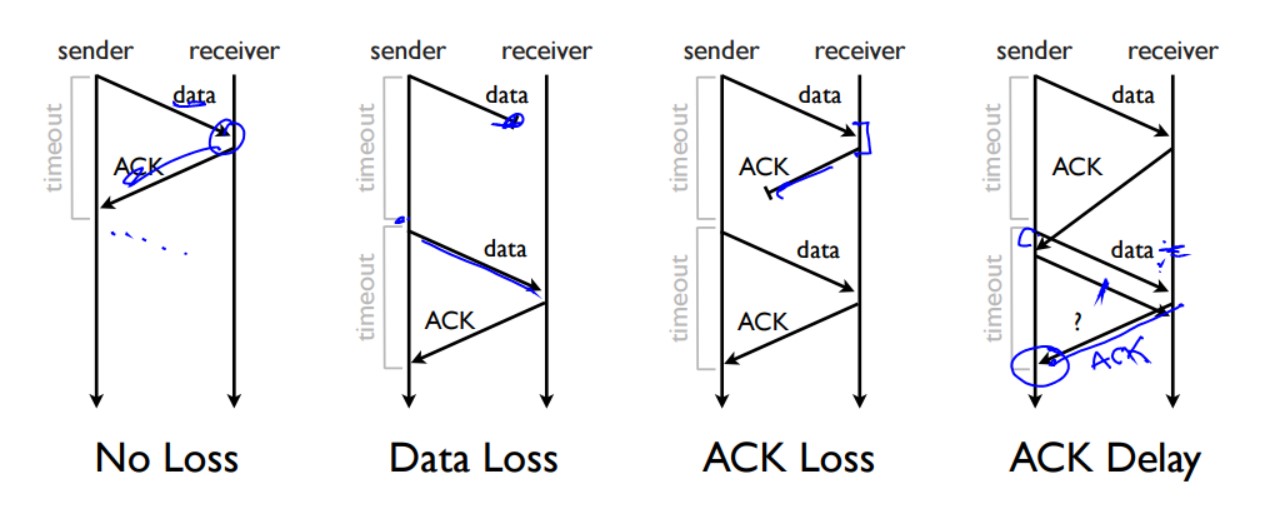
当ACK延迟时,发送方重传数据报,重传完毕后收到了ACK然后又发送第二个包,那么此时的接收方返回的ACK就很暧昧了,因为发送方不知道这个ACK是重传包的ACK还是二号包的ACK。
为了避免这种定义不明的问题,通信双方会给自己的数据报加上标号,这样就可以区分返回的ACK到底是对应的哪个数据报。

滑动窗口
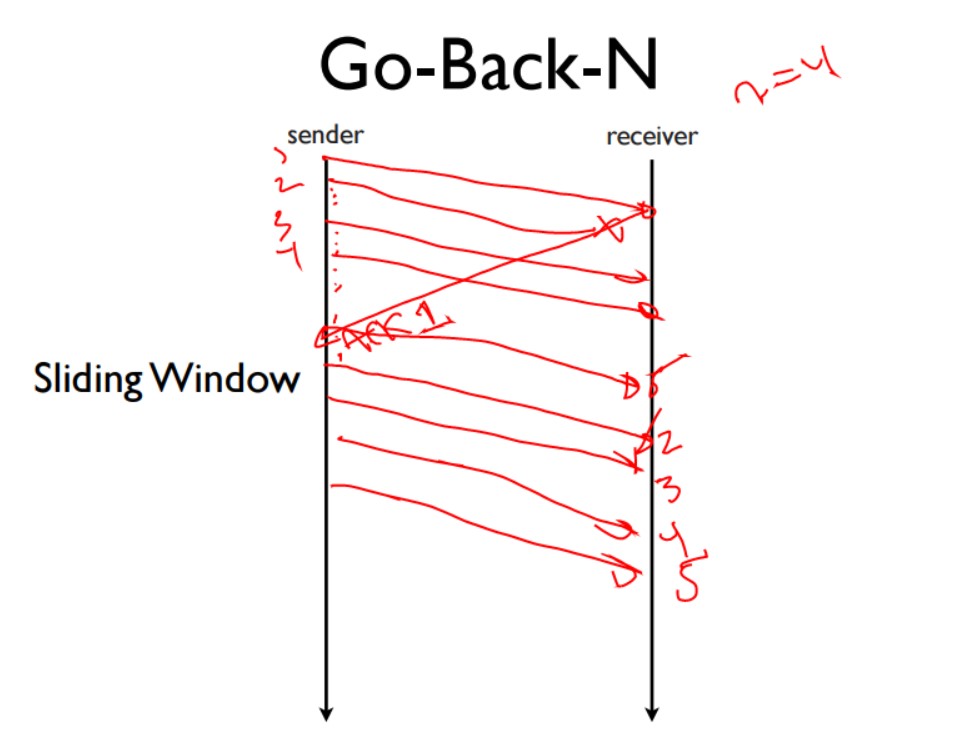
停止-等待协议很简单,但是很明显效率很差,因为通信双方要不断的等待单个数据报在链路上往返传递。发送n个数据报就要等待n个往返时间,所以为了提高效率滑动窗口诞生了。
滑动窗口与停止-等待协议相比区别就在于它不再是发一个包就停止,然后等待ACK了,而是发送一个窗口容量那么多的包,然后等待一个窗口容量那么多的ACK。下面是滑动窗口容量为3时的数据报走向

发送端的滑动窗口
滑动窗口维护着三个变量,发送窗口的大小(SWS)、最后一个收到的ACK(LAR)、最后发送的窗口号(LSS),也就是发送端发送的最新的窗口不应该超过LAR+SWS,当然如果超过了会被接收方丢弃。这种传输方式也存在问题比如发送了标号为7,8,9的包,8,9都已经收到ACK了但是7一直未收到,在这种情况下滑动窗口不会前进,也就是发送端会一直等待7的ACK直到超时。

接收端的滑动窗口
接收端的滑动窗口也维护这三个变量接收窗口的大小(RWS)、可被接收的标号(LAS)、最新收到的标号(LSR),接收方可接收的范围是(LAS-LSR)<=RWS。值得注意的一点是接收端返回的ACK标头是期待收到的包,而不是已经收到的包,另外接收方返回的ACK是一个累计确认,它代表的不是收到了什么而是连续数据是什么,也就是说收到了6,7,8,15然后返回8,意味着收到了9之前全部的连续的数据报,而不是仅收到了8。

滑动窗口的大小
接收窗口和发送窗口总是大于1。发送窗口总是大于或小于接收窗口这是因为如果接收窗口大于发送窗口,那有一部分接收窗口容量将永远的用不到,也无法很好的利用接收方的Buffer。

重传策略
Go-Back-N是一种悲观的重传策略,当一个包丢失后,它会重传该包和其后所有的包
Selective Repeat则是一种乐观的策略它只重传没有收到ACK的包

TCP 报头
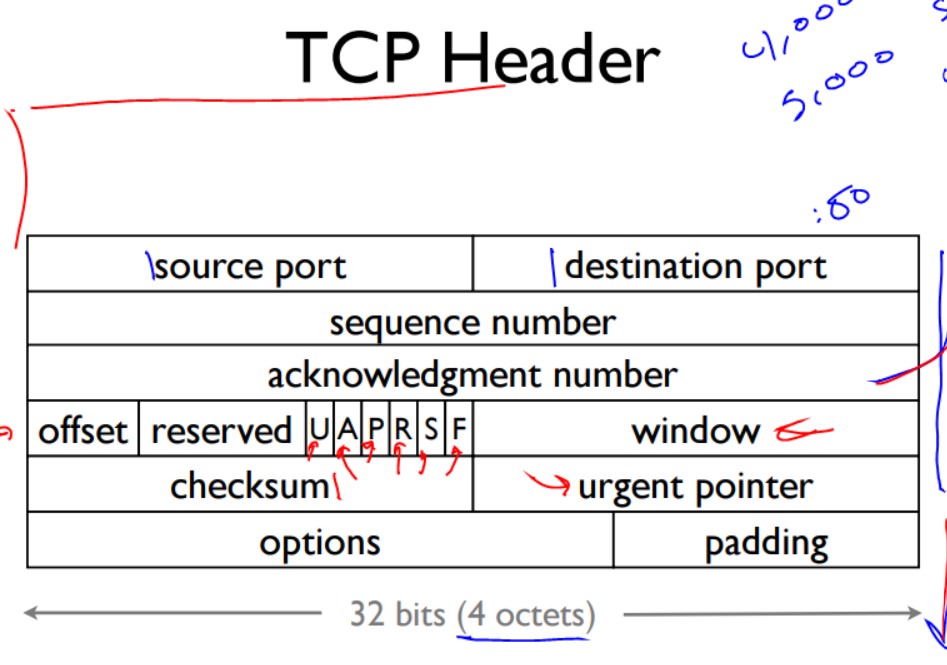
标准的TCP长度为20个字节(20个八进制数)
- sequence number:数据报序号
- acknowledgement number:对方应返回的确认号
- window:窗口大小
- UAPRSF:
- urgent bit该数据报非常紧急,如果设置了urgent bit那紧急指针指向紧急数据在段中的位置
- ACK 如果acknowledge number是合法的就置为1
- push bit紧急度低于urgent
- Reset bit发生错误要复位连接
- SYN:第一次发包时没有ACK位,只有SYN位,然后设置sequence number,标记此包为第一个包,出于安全sequence number不是从0开始而是随机开始
- FIN 表明要断开连接
- offset:由于有option的存在所以数据的位置是不确定的offset指明了数据的开始位置




